|
|
|
Le Big Data et le data mining Le data mining (III) Lorsque la partie matérielle est opérationnelle, que le système d'exploitation est installé et les sources de données identifiées, il faut à présent les combiner à des outils de gestion, d'analyse et de visualisation de données, ce qu'on appelle une application de "data mining" et éventuellement des services de distribution. Le "data mining" représente toutes les technologies susceptibles de rechercher et d'analyser les informations contenues dans les bases de données. On appelle également ce processus l'analytique. C'est un outil de prospection visant à trouver des structures originales et des corrélations informelles entre des données. Il permet de mieux comprendre les liens entre des phénomènes en apparence distincts et d'anticiper des tendances encore peu discernables.
Cette spécialité fait appel à des technologies à la croisée de la gestion des bases de données, de l'intelligence artificielle, des systèmes experts et des statistiques. Parmi les méthodes utilisées citons la classification, les réseaux neuronaux, l'arbre de décision, SEMMA, Six Sigma, etc. Hadoop Quand on aborde la question des logiciels gérant le Big Data, s'il y a une plate-forme que connaissent bien tous les spécialistes, c'est "Hadoop". Développé en 2005 par deux ingénieurs de Yahoo, Hadoop est aujourd'hui géré par la fondation Apache, déjà propriétaire de plus d'une centaine de projets ou applications open-source dont le fameux serveur web Apache HTTP server. Hadoop est un système d'exploitation écrit en Java qui permet de piloter des machines et de créer des applications distribuées et échelonnables (scalable) adaptées à la gestion du Big Data. Il supporte donc le traitement en parallèle de très importants volumes de données de différents formats (non structurés), ce que ne peuvent pas réaliser les logiciels classiques.
A titre d'exemple, Hadoop est capable de gérer des fichiers de 500 millions d'enregistrements d'appels quotidiens, de transformer les 10 TB de Tweets créés chaque jour en données d'analyses visuelles ou de convertir 100 milliards de relevés annuels de compteurs d'électricité en tendances pour mieux prédire la consommation d'énergie. Hadoop comprend quatre principaux composants : - Common : une bibliothèque et des utilitaires utilisés par les autres modules - HDFS : un file system distribué dérivé du GFS inventé par Google - YARN : une plate-forme de gestion des ressources des clusters - MapReduce : un modèle de programmation (dérivé du produit du même nom créé par Google) qui transforme les données indépendamment de leur échelle ou de leur format, les cartographie, les rassemble (avec ou sans réduction de données) et met les résultats à disposition du HDFS. Hadoop étant ouvert et gratuit, de nombreux développeurs ont créé des modules complémentaires dont InfoWorld a dressé une liste de 18 outils essentiels parmi lesquels HBase, Mahout, NoSQL, etc. Hadoop a été adopté par tous les majeurs de l'informatique dont Google, Amazon, Facebook, IBM, SAP, etc. Ceci dit, Hadoop n'est qu'une plate-forme logicielle parmi d'autres et certaines sont aujourd'hui plus performantes. Toutefois, son avantage est sa gratuité, un facteur vital pour une entreprise, dans un marché où le prix des plates-formes s'affiche souvent en cinq ou six chiffres devant la virgule. Parmi les logiciels de data mining, de modélisation et de visualisation citons : BigQuery, Cloudera, ClickFox, CR-X, Greenplum, Netezza, SAS Enterprise Miner, Noduslab, Textexure, Web2DNA, Cytoscape, BayesiaLab, RapidMiner, Synthesio, Tableau Software, CaptainDash ou encore Webmasters. Cette technologie s'applique à tous les secteurs intéressés par l'analyse quantitative où les enjeux dépendent notamment du nombre de paramètres analysés. Parmi ces secteurs citons l'espionnage, les forces armées, le contrôle du trafic (aérien, routier, etc), l'agriculture, l'éducation, la santé, la bioinformatique, la finance, l'économie, le marketing, les sondages, les analyses du web, de la blogosphère et de nombreux domaines scientifiques (physique, chimie, biologie, biotechnologie, botanique, entomologie, météorologie, sismologie, astrophysique, cosmologie, épidémiologie, médecine sportive, etc.).
A voir : Analyse
des données textuelles avec SAS Text Analytics
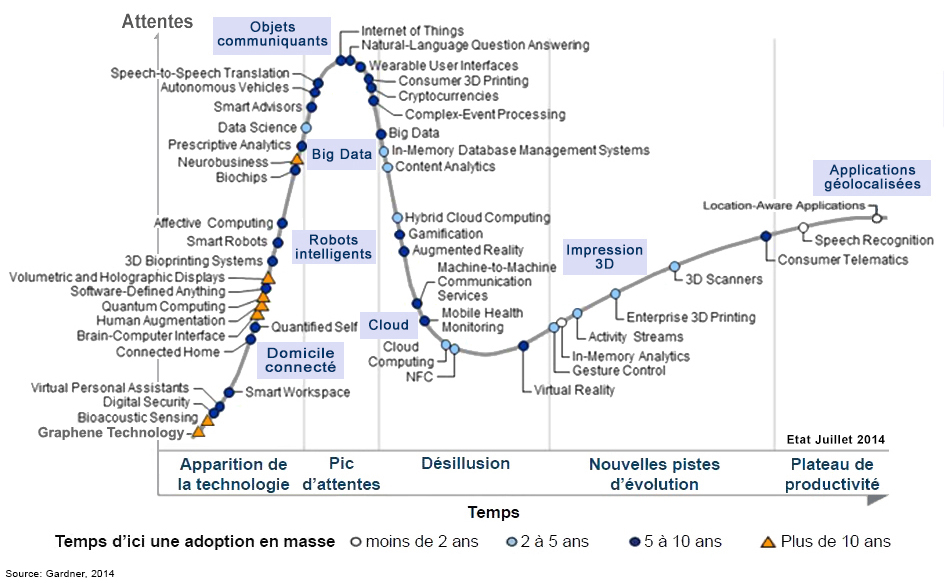
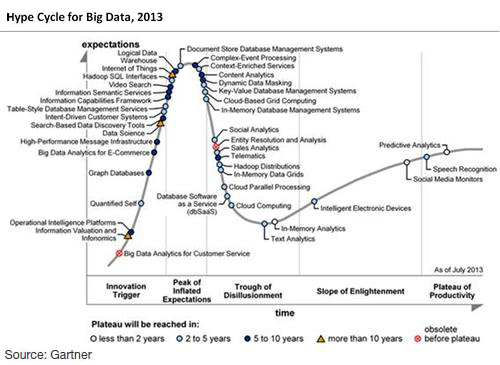
Les machines intelligentes Lorsque les technologies du Big Data seront utilisées à grande échelle (plateau de production du Hype Cycle), nos appareils électroniques et autres terminaux connectés deviendront plus intelligents et plus autonomes. En effet, avec l'Internet des Objets qui est en pleine expansion et la multiplication des capteurs sur les appareils domestiques, le Big Data combiné au concept "Machine to machine" (M2M) va ouvrir de nouvelles opportunités aux entreprises, parmi lesquelles : - Rendre les données plus transparentes, plus accessibles et dans des délais plus courts. Cela concerne les données des administrations publiques y compris les centres de recherches, l'industrie (R&D) et tous les secteurs proposant des produits à leur clientèle, - Personnaliser les produits et les services. Les publics seront profilés de manière de plus en plus précise afin de pouvoir adapter les services aux besoins de l'individu, un approche déjà appliquée dans le marketing ou la gestion des risques, - Assister les prises de décisions humaines grâce à des algorithmes automatisés. Les méthodologies d'analyse complexes améliorent les processus décisionnels en minimiser les risques et en apportant de nouvelles données à très haute valeur ajoutée qui jusqu' à présent étaient ignorées, - Offrir des opportunités en termes de modèle d'affaire (business model), de nouveaux produits et de services. Ainsi, l'externalisaiton ouverte (crowdsourcing) permet aux entreprises d' améliorer leur produits en fonction du feedback et des desiderata des clients et de créer ainsi des innovations dans le service après-vente (par ex. la valorisation des données de géolocalisation en temps réel permet de créer des services mobiles d'assistance aux conducteurs et aux piétons). A
voir : Le
Data Mining en 35 leçons Introduction to Hadoop, by Cloudera/U.Stanford Intro to MapReduce, by MapR Academy
Un changement de paradigme Ainsi qu'on le constate, le Big Data offre potentiellement aux entreprises et aux agences gouvernementales (NSA, DARPA, etc), les moyens d'aller au-delà de la simple information, elles deviennent une source d'innovations potentielles. Au cours de la conférence sur la "Technonomie", parlant des volumes d'informations qui s'accumulent, Eric Schmidt déclara que "les gens ne sont pas prêts pour la révolution qui est en train de se produire". En effet, le Big Data c'est une révolution en soi car on ne travaille plus sur de petits volumes de données et un résultat en différé, mais sur des volumes gigantesques représentant la totalité des données récoltées, tout en pouvant travailler en mode interactif voire en temps réel. Si les scientifiques exploitent le Big Data depuis quelques décennies, c'est dans le marketing que cette technologie est la plus avancée. Les analystes ne cherchent plus à établir des moyennes statistiques mais recherchent des informations pertinentes et représentatives.
Ainsi, déclarer qu'en moyenne les hommes de 50 ans sont mariés et roulent en voiture familiale ne veut rien dire dans l'esprit d'un célibataire du même âge qui roule en coupé. C'est justement l'existence de ce type de profil qui révèle la fracture entre ce que disent les statistiques et la réalité et où le Big Data offre tout leur intérêt. En effet, grâce au Big Data, on sort des moyennes et des segmentations de marché par exemple qui ne représentent personne en particulier, pour analyser les comportements individuels, mettre en évidence les tendances et identifier les anomalies et leurs causes avec un niveau de granularité excessivement fin afin d'extraire le profil de la moyenne. Ainsi, quand on travaille avec le Big Data, la loi de Pareto des 80-20 (80% des revenus sont produits par 20% de la population ou de manière générale en socioéconomie 80% des effets sont produits par 20% des causes) n'a plus de sens, pas plus que les autres techniques et stratégies de prospection basées sur les moyennes statistiques. C'est ainsi que si vous essayez d'appliquer à vous-même les résultats d'une étude statistique par nature basée sur un échantillon d'une population donnée, deux cas de figure se présentent : soit en moyenne vous correspondez au profil concerné (l'exemple de l'astrologie est typique : chaque individu se retrouve "plus ou moins" dans chacun des signes) soit vous êtes aux extrémités de la courbe en cloche et donc pratiquement atypique. Or la réalité infirme ces études statistiques même si elles gardent toute leur pertinence pour les calculs des assurances notamment. Dans ce contexte, les anciennes méthodes marketing et les anciennes technologies ne sont donc plus valables, rendant toute la logique du marketing direct par exemple et les systèmes d'information de l'ancienne génération obsolètes car on change de paradigme en termes conceptuel, d'architecture et de traitement. C'est une révolution ! Le Big Data change également notre façon d'analyser les données et donc de voir la réalité. Jusqu'à présent, on allait chercher les données qu'on introduisait dans un processus pour obtenir un résultat. C'est le programme qui interrogeait le monde extérieur. Avec le Big Data, c'est le processus inverse : on laisse parler les algorithmes et ce sont les données qui nous interpèllent et nous apprennent quelque chose. Autrement dit, c'est le traitement qui va chercher la donnée et non plus la donnée qui vient s'ajouter au traitement. Pour un analyste, cette manière de concevoir l'analyse de donnée est très avantageuse car elle révèle des phénomènes tangibles et des tendances que ne peuvent pas percevoir une étude statistique. Ainsi, en analysant le Big Data des ventes de certains sites marchands on découvre par exemple qu'une augmentation de la concentration des pollens dans l'air augmente les ventes de shampooing ou que les personnes ne s'inscrivent pas sur les sites de rencontres payants les jours où il y a beaucoup d'embouteillages. Ces informations très concrètes sont accessibles sans même devoir réaliser de sondage.
En revanche, restons réalistes. Si d'aucuns considèrent que le Big Data est une révolution, elle représente un potentiel; ce n'est pas une finalité en soi ni même le seul moyen pour une entreprise d'arriver à ses objectifs. L'exploitation du Big Data n'est pas nécessairement adaptée à tous les métiers ou tous les médias. L'analyse des données de Facebook par exemple ne va pas permettre à un fabricant d'améliorer son contrôle qualité. Il aura toujours besoin de Lean Six Sigma ou d'autres méthodes d'analyses. Un gestionnaire d'assurances ne trouvera pas ses clients sur Twitter mais plutôt dans un logiciel de CRM (Customer Relationship Management). Il faut aussi des hommes et du savoir-faire pour installer ces plates-formes, gérer les données et leur donner du sens et de la valeur. C'est le rôle des architectes informatiques, des développeurs et des analystes notamment, le client se limitant à exploiter le service. C'est ainsi que dans le cadre du modèle SAO (Service Oriented Architecture) émergent des fournisseurs de données qui offrent l'opportunité aux entreprises et aux particuliers d'accéder plus facilement aux informations qui deviennent également plus abordables et plus simples à gérer puisque la complexité du Big Data est transparente pour le client. En conséquence, tout le monde s'enrichit car chacun peut acquérir des connaissances, comprendre de nouveaux phénomènes et anticiper de nouvelles tendances. L'Open Data Pour supporter la révolution que représentent le Big Data et encourager le partage comme l'exploitation de ces données, parallèlement à l'émergence des fournisseurs de données (concept DaaS) se développe le concept d'Open Data. A terme, on peut envisager la fusion des trois concepts. A l'instar de Google qui offre gratuitement certains services aux internautes, à la demande des autorités européennes (directives PSI de 2005 et INSPIRE de 2007) et suivant les recommandations émises par l'organisation W3C en 2009, les administrations publiques ont été priées de mettre leurs données publiques à la disposition des citoyens. C'est le concept "Open Data".
L'Open Data évolue dans les mêmes dimensions que le Big Data, à la différence que les données sont authentiques, non discriminatoires, non propriétaires et libres de droits. Toutefois, les sources et les formats de ces données étant très variés et souvent incompréhensibles pour la majorité du public (le cas des données techniques), des plates-formes technologies ont été développées exploitant des interfaces (API) standards pour pallier à ce manque de standardisation. Les utilisateurs des Open Data sont également demandeurs de formats simplifiés tels que CSV, JSON, XML et le flux RSS. Les Open Data concernant toutes les données du secteur public à travers le monde, le cadre juridique souffre de quelques lacunes. Ainsi, concernant la libre circulation des données, le droit d'auteur et le droit des bases de données prévalent en Europe, alors que les Anglo-saxons disposent de la licence Creative Commons dédiée aux Open Data. Il existe toutefois des projets universels relativement avancés tels que les licences ODbL (en français) et OKFN. Ces Open Data doivent être disponibles sur tous les ordinateurs des particuliers, y compris les mobiles. Quelques exceptions sont toutefois prises en compte comme la géolocalisation qui bénéficie d'un cadre légal particulier, tandis que les données à caractère privé, relatives à la sécurité ou portant atteinte aux droits d'un tiers ne sont pas publiées. Parmi les Open Data, il y a les collections des musées tombées dans le domaine public et en libre accès. Ainsi, en 2014 le Musée Métropolitain d'Art de New York a mis sur Internet quelque 400000 documents extraits de ses collections encyclopédiques. Libre de droits et de toute restriction, ces documents peuvent être utilisés par tous les médias. Concernant les applications Open Data, citons HealthMap dans le domaine de l'épidémiologie et de la santé qui permet gratuitement à toute personne intéressée de consulter l'état sanitaire de sa région ou du monde grâce à une surveillance en temps réel de l'apparition des maladies et des menaces de santé publique. L'application développée en 2006 par des chercheurs, des épidémiologistes et des développeurs américains extrait les informations sanitaires disparates de 11 sources authentiques du web (dont l'OMS, la FAO, WDIN, Eurosurveillance, Geosentinel, ProMED, Google News, etc) et recherche dans leurs données les rapports officiels validés, les bulletins d'alertes, les actualités, les témoignages de témoins oculaires et les commentaires d'experts parmi d'autres informations, les trie et les analyses afin d'en extraire des informations utiles qu'elle présente sous forme géolocalisée sur une carte du monde et sous forme d'actualités et de commentaires. HealtMap est en ligne depuis 2012.
Etat sanitaire du monde début 2016 tel que présenté par l'application HealthMap. Devant les mutations politiques, sociales et cognitives auxquels nous assistons, en 2012 dans son livre-manifeste "Petite Poucette", le philosophe Michel Serres lança un appel aux dirigeants comme au public sur la nécessité de réinventer la vie en communauté, le rôle des institutions, la manière d'être et de connaître. Il soulève clairement la question de l'usage du Big Data et l'Open Data et du pouvoir de ceux qui disposent de ces informations, évoquant l'éventuel "avènement d'un cinquième pouvoir, celui des données, indépendant des quatre autres, législatif, exécutif, judiciaire et médiatique". Son manifeste a visiblement trouvé un écho avec l'émergence depuis 2013 du concept "Data as a Service" évoqué précédemment. En guise de conclusion L'exploitation du Big Data a commencé par un besoin économique : savoir qui achète quoi. Ensuite les scientifiques et notamment les chercheurs en médecine et pharmacie ont eu besoin de Big Data pour établir des similitudes entre pathologies ou entre les patients. Enfin, les sociétés d'assurances et les organisations gouvernementales ont toujours voulu connaître le profil de la population.
Quoique certains disent, notre société a besoin d'information et de les analyser, que ce soit dans le cadre de la lutte contre le terrorisme, la lutte anti-fraude mais également à des fins de recherche, y compris à titre privé, et de marketing ciblé (le fameux "IP tracking" et les "cookies") parmi d'autres activités. Google comme IBM ou Microsoft et la plupart des sociétés de développements informatiques ainsi que les réseaux sociaux tels que Facebook et LinkedIn et des sociétés de services comme Amazon et Monster sont déjà des fournisseurs de données exploitant le data mining et se ventent ainsi d'être très réactifs et de pouvoir cerner les habitudes et les besoins des internautes. A travers les sevices offerts par ces entreprises, on se rend compte que la collecte et l'analyse de grands volumes de données au fil de l'eau offrent des avantages très séduisants. Parmi ceux-ci citons la personnalisation des services au client, l'optimisation des processus métier et l'amélioration des performances des employés. Grâce à des capteurs externes et des analyses en temps réel, la gestion du Big Data transforme également les machines de simples outils en assistants intelligents (par ex. les voitures), le même principe pouvant s'appliquer aux ressources d'une ville vis-à-vis des besoins de sa population, ce qu'on appelle les "smartcities". Enfin, les technologies du Big Data développent des métiers spécifiques : data analyst, data scientist, data officer et autre data miner compteront certainement parmi les métiers d'avenir. Si les technologies du Big Data sont performantes et séduisantes, ce qui l'est moins est de tromper les utilisateurs et d'abuser de leur confiance en collectant ses données à caractère privé. Si la législation doit protéger l'intérêt des clients et des internautes, elle ne doit pas pour autant être un frein au développement. On ne peut pas perdre de vue la compétitivité, les pratiques commerciales et les opportunités qu'offrent le Big Data.
Sachant que tout est connecté et le sera encore bien plus à l'avenir, sur le plan économique, les gouvernements ont bien compris l'intérêt du Big Data. L'Union européenne en a fait une priorité dans son 7eme Programme Cadre (FP7) qui concerne les outils financiers de la recherche scientifique. Un budget de 9.1 milliards d'euros fut alloué à l'ensemble des ICT des Etats européens pour la période 2007-2013. La France consacre 25 millions d'euros au Big Data dont 700000€ pour le programme Mastodons du CNRS démarré en 2012 et qui comprend plus de 16 projets. Pour la période 2014-2020, dans le cadre de son programme Horizon 2020, l'Europe dispose d'un budget global de 80 milliards d'euros dédiés à la recherche et à l'innovation (un nouveau portail web est en cours de construction). Un appel d'offre a par exemple été lancé d'un montant de 658.5 millions d'euros (ICT-15-2014, deadline 23/04/2014) dans le cadre du Big Data et Open Data. Enfin, en 2011, le président Barack Obama proposa son "Big Data Plan" assorti d'un budget de 200 millions de dollars pour la recherche et le développement. Le Big Data est à notre portée. A présent, il faut l'exploiter. Pour plus d'informations En français L'affaire PRISM (Echelon), sur ce site Usine Digitale, rubrique Big Data (website) Big Data TV, YouTubeLe Data Mining en 35 leçons, YouTube Les entreprises européennes sont-elles prêtes pour le Big Data, Steria, 2013 En anglais Big Data, IDC's Digital Hub Big Data Visualization: Review of the 20 Best Tools, Edoardo L'Astorina 50 Great examples of Data Vizualization DARPA Innovation Information Office (I2O dont le programme Memex) Here's The $2 Billion Facility Where The NSA Stores And Analyzes Your Communications, Business Insider, 2013 How the U.S. Government Hacks the World, Bloomberg BusinessWeek, 2013 The Big Data Revolution, CNRS, 2013 3D Data Management (3V), Gartner, 2001 Big Data, Smart Computing Blog Hadoop, Apache Hadoop on Google Cloud Platform, Google The Digital Universe in 2020, IDC (rapport), 2012 A Very Short History of Big Data, Mashable, 2012 How Big Data Became So Big, The New York Times, 2012 Internet of Things by 2020, Gartner, 2013 Disrupting Technologies (2025), McKinsey, 2013 The Evolving Internet (2025), Cisco, 2010 Information (taille de différents objets en terme de bits d'information nécessaires pour les décrire) Entreprises, startups et conseils en TIC Big Data Vendors 2013, Hadoop Wizard Horizon 2020 (portail), Commission européenne Agence Wallonne des Télécommunications (@wt.be)
|
|||||||||||||||||||||||||||||||||||||||||||||