|
|
|
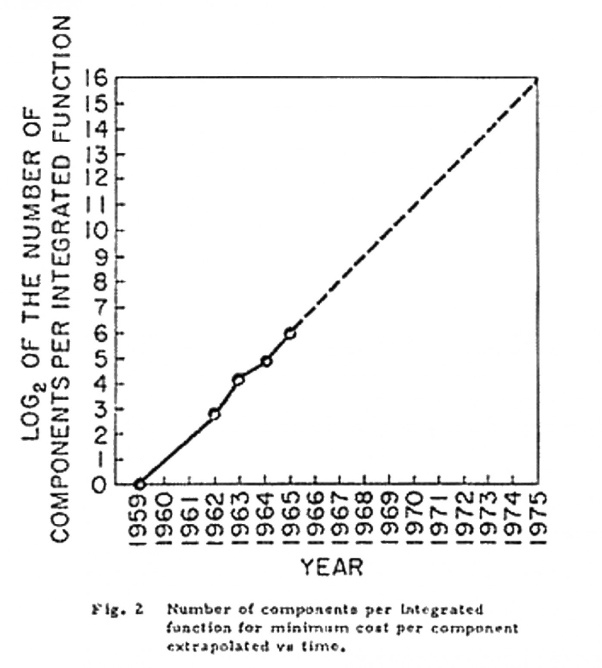
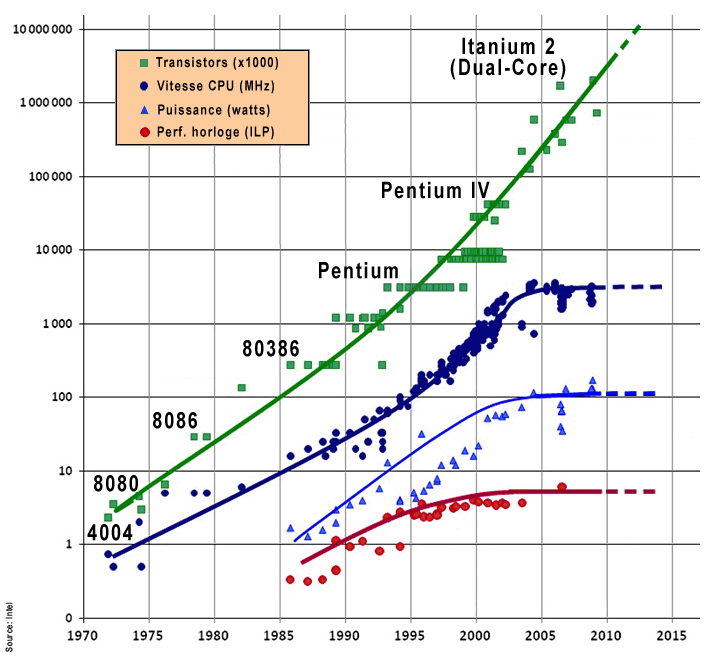
La loi de Moore Les tendances à l'ère des circuits intégrés En 1965, le Dr. Gordon E. Moore alors ingénieur chez Fairchild Semiconductor publia un article dans "Electronics Magazine" dans lequel il expliqua que la complexité des circuits intégré d'entrée de gamme doublait tous les deux ans à prix constant depuis 1959, année où les premiers circuits intégrés furent disponibles. Moore reformula sa loi en 1975, précisant que ce n'est pas les circuits intégrés qui deviennent plus complexes (car ils comprennent des unités indépendantes) mais c'est le nombre de transitors contenus dans les microprocesseurs qui double tous les deux ans. En effet, on constate qu'entre 1971 (année où les premiers microprocesseurs Intel 4004 utilisèrent des transistors et offraient une puissance de calcul de 92000 opérations par seconde soit 0.092 MIPS à 0.740 MHz) et 2001 la puissance des ordinateurs a doublé en moyenne tous les 1.96 an. Une tendance militaire voudrait même que ce taux s'établisse en l'espace de 15 à 18 mois. C'est une conséquence de la miniaturisation croissante des composants électroniques qui touche également les mémoires des ordinateurs. On observe une progression technologique constante qui s'est même accélérée pour les processeurs depuis ~1995 et la sortie des Pentium. L'ordinateur IBM 1401 commercialisé en 1959, l'un des premiers systèmes transistorisés, représente bien la loi de Moore. En effet, comparé à la technologie actuelle, l'IBM 1401 coûtait 2 millions de dollars, il pesait 4 tonnes, son unité centrale occupait plus d'un mètre cube et il effectuait 4000 opérations par seconde. Aujourd'hui, le GSM le plus simple coûte 50 €, pèse 100 g et tient dans la paume d'une main. Il dispose d'un chip de la taille d'un ongle et effectue 1 milliard d'opérations par seconde ! Autrement dit, la puissance des ordinateurs augmente d'un facteur 100 tous les 10 ans pour un coût à peu près constant. En 50 ans les ordinateurs sont devenus 250000 fois plus rapides et accessoirement, miniaturisation aidant, leur volume a été divisé dans les mêmes proportions ! L'évolution fulgurante des processeurs Ce progrès impressionnant est avant tout lié à l'évolution des microprocesseurs. IBM et Intel ainsi que ATI/AMD et NVidia sont en compétition dans ce segment et se font une guerre féroce depuis des décennies. Ainsi, le processeur Intel 8088 installé dans les PC XT en 1981 était à peine plus large qu'un doigt en tenant compte de son boîtier. Tirant profit de la technologie HMOS ou CHMOS, il contenait 29000 transistors, des canaux de 3 microns, une architecture 8 bits et 40 pins alimentées en 5 V pour une cadence de 4.77 MHz. Sa puissance de calcul atteignait 750000 instructions par seconde ou 0.750 MIPS à 10 MHz. A
lire : Moore's
Law, Intel Cramming more components onto integrated circuits (PDF), G.Moore, 1965 (la loi de Moore publiée dans le magazine "Electronics")
20 ans plus tard, en 2001, le processeur Pentium IV cadencé à 3.4 GHz était cinq plus large que le 8088, contenait 175 millions de transistors, il exploitait la technologie VLSI, disposait de 423 pins, de canaux de 0.18 micron, d'une architecture 32 bits et était alimenté en 1.75 V. La même année, IBM commercialisa le premier processeur double-coeur de 64 bits, le POWER4 cadencé à 1 GHz. Contenant 174 millions de transistors. Il offrait un taux de transfert ou débit interne (throughput) supérieur à 100 GB/s dans le cache mémoire L2 et de 35 GB/s de coeur à coeur ! Notons qu'il exploitait la technologie CMOS 8S3 et l'intégration SOI, l'une des plus avancées. En 2007, IBM sortit le processeur dual-core le plus rapide, le POWER6 cadencé à 4.7 GHz dont le processeur en technologie de 65 nm et contenant 790 millions de transistors. C'est également en 2007 qu'Intel entra dans "l'ère du teraFLOPS". Le constructeur américain présenta le Polaris, un nouveau processeur CMOS multi-coeur gravé en technologie de 65 nm cadencé à 6.26 GHz, contenant 80 coeurs de processeurs. Sa vitesse de calcul atteint 2 TFLOPS[1] soit la rapidité d'un superordinateur Cray ! Il est avant tout destiné à la recherche.
C'est l'entreprise japonaise NEC qui entra en force sur le marché des superordinateurs en 1983 en proposant déjà à cette époque un système de 1 TFLOPS alors que les PC balbutiaient encore à 4400 FLOPS (PC XT cadencé à 4.4 MHz) ! En 2017, IBM présenta les premiers microprocesseurs FinFET (Fin Field-Effect Transistor) en technologie de 7 et 5 nm. Puis en 2021, IBM annonça la fabrication du premier microprocesseur en technologie de 2 nm exploitant des transistors GAA (Gate-All-Around). A puissance égale, il est 47% plus performant que le précédent modèle en technologie de 7 nm. 50 milliards de transistors ont été placés sur un chip de 1 cm2. En 2024, Intel commercialisera des processeurs 20A et 18A en technologie 1.8 nm fabriqués par ASML sur des machines lithographiques UVE. ASML annonça également qu'il exploitera la technologie 1 nm vers 2028 (cf. WCCFTech). Cette fois la technologie classique a pratiquement atteint ses limites car le silicium ne permet pas de graver des transistors inférieurs à 1 nm. Il faut à présent changer de technologie et utiliser par exemple des nanotubes en carbone. On y reviendra. Quant aux derniers superordinateurs (cf. le palmarès du TOP500), le record de vitesse de calcul est actuellement détenu par le Fugaku japonais qui atteint 415.53 PFLOPS. Juste derrière lui vient le Summit d'IBM qui atteint 148.6 PFLOPS. En 2023, le DoE (U.S. Department of Energy), la NNSA (National Nuclear Security Administration) et le LLNL (Lawrence Livermore National Laboratory) disposeront du superordinateur El Capitan de HPE dont la vitesse de calcul atteindra 2 exaFLOPS (crête). Ceci dit, cette performance se paye au prix fort. Le programme complet d'El Capitan revient à 600 millions de dollars. Le Fugaku représente un coût total de 1 milliard de dollars. Rappelons qu'une application distribuée comme Einstein@Home présentait en 2021, grâce aux 13000 ordinateurs mis à son service, une puissance globale de calcul supérieure à... 2.7 exaFLOPS ! Le prix de cette infrastructure distribuée revient à environ 15 millions de dollars soit au moins 40 fois moins cher qu'un superordinateur de dernière génération. Même progression en puissance et chute de prix pour les processeurs graphiques. Aujourd'hui, un ordinateur ne peut plus se contenter d'un processeur unique (contenant les instructions programmées, le compteur, les registres de données et la mémoire) pour gérer tous les calculs dont les opérations se comptent par milliers de milliards par seconde (en TFLOPS) par processeur. Le processeur est devenu... un système multi-coeur (dual-core, quad-core, 8-core, etc) voire même une carte processeur. C'est en particulier le cas des cartes graphiques sur lesquelles nous reviendrons. A consulter : Evolution des chips Intel (poster PDF), Intel
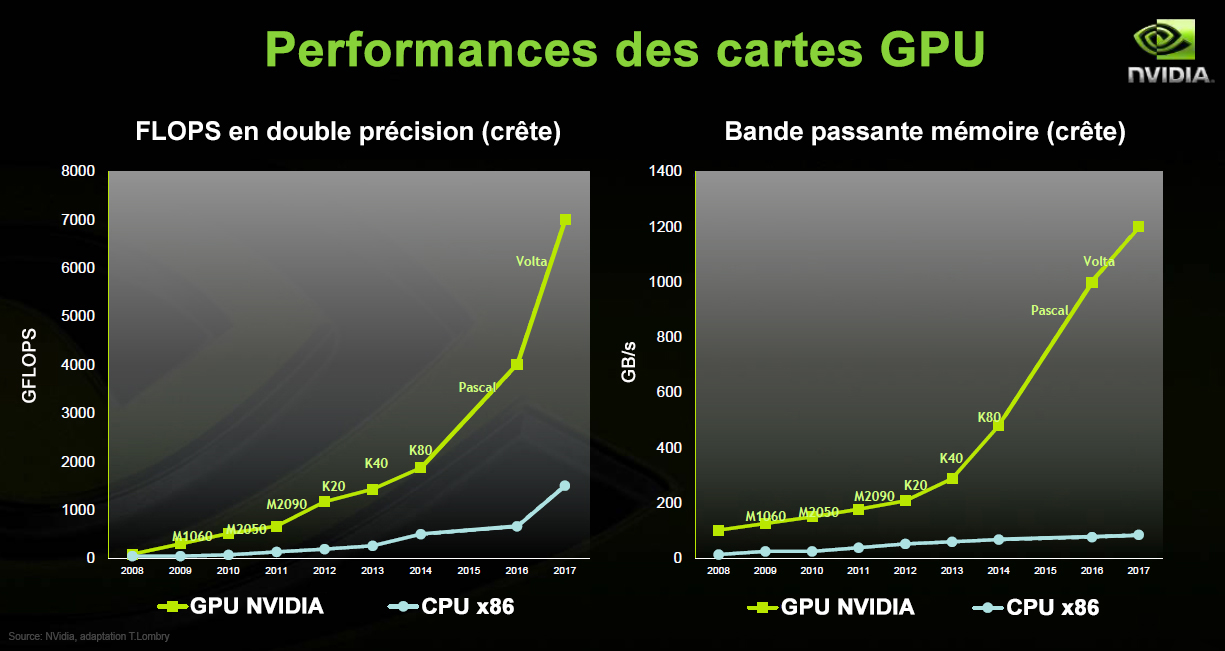
En 10 ans, les performances des cartes graphiques ont été multipliées par 1000 et par 2000 en 15 ans ! Ainsi la carte graphique Nvidia FX 5500 en architecture NV34B sortie en 2003 présentait un score benchmark de seulement 8 mais c'était suffisant pour du travail bureautique ou des jeux très simples. Or à la même époque ATI et Nvidia proposaient déjà des cartes 10 fois plus rapides. Quelque 24 générations de GPU plus tard, l'avant-dernière génération de carte graphique explose les compteurs avec un score benchmark de 13900 pour la Nvidia TITAN Xp en architecture Pascal sortie en 2017 ! La nouvelle carte graphique Nvidia GV100 en architecture Volta a pulvérisé ce plafond en 2018 et comme l'explique cet article de l'ORNL, elle fut de suite exploitée dans les superordinateurs HPC du département américain de l'Energie (DoE). Le progrès est tellement rapide et l'obsolescence garantie qu'en 10 ans le prix d'une carte graphique est divisé par 10 ! Toutefois, comme toute avancée technologique le prix des nouveux modèles haut de gamme reste élevé (800-1500 € voire 3000 € pour le modèle le plus récent).
Ce progrès continu permet depuis quelques années d'utiliser les cartes graphiques dans les appareils mobiles, smartphones et autres tablettes. Ainsi, si on prend pour référence l'iPhone 4 de 2010, le Galaxy Tab S2 sorti l'année suivante était 10 fois plus rapide et l'iPad 4 sorti en 2012 était 50 fois plus rapide ! Bien sûr, les prix s'alignaient aussi avec leurs performances. Aujourd'hui, un smartphone haut de gamme revient à plus de 1000 € soit le prix d'un ordinateur de bureau ou d'un portable de qualité. Enfin, comme l'ont constaté Intel et Google, ce n'est plus tant la température des processeurs (elle peut atteindre 120°C sur un Polaris) qui écourte la durée de vie (MTBF) des systèmes mais la façon dont la carte-processeur est conçue et s'interface avec les autres circuits intégrés et notamment les mémoires DRAM (cf. l'étude de Bianca Schroeder et al. publiée en 2009). Les mémoires de masse A son tour, les mémoires de masse ont fait l'objet d'une évolution spectaculaire. En 1979, un disque dur de 250 MB pesait 250 kg, il coûtait 10000$ et devait être transporté sur un chariot. Aujourd'hui, le plateau d'un disque dur Seagate en technologie SMR mesure 2 cm2 et offre une capacité de 3 TB (cf. cette photo). Une carte flash microSD de 64 GB mesure 1.65 cm2, pèse 4 g et coûte 40$ !
Aujourd'hui, la plupart des ordinateurs domestiques disposent d'un disque dur SSD, c'est-à-dire en technologie Flash (cf. le marché informatique) car ils sont 10 fois plus performants et 30 fois plus rapides qu'un disque dur traditionnel. Selon les marques, un disque SSD de 1 TB coûte entre 50 et 400 € (2021) alors qu'ils étaient entre 4 à 10 fois plus chers 10 ans auparavant. Depuis quelques années, les nouvelles technologies combinant l'enregistrement magnétique et les semi-conducteurs permettent de contrôler l'état d'un seul atome à partir de l'état de spin de l'électron. Cette technologie permettrait d'atteindre une capacité de 200 TB par cm2 voire supérieure ! Les algorithmes et la loi de Moore Les algorithmes suivent-ils la loi de Moore ? La question comprend deux volets : celle concernant la vitesse des processeurs en fonction de la densité des coeurs et celle des algorithmes série vis-à-vis du traitement parallèle. En analysant le rapport de Sematech on apprend que la vitesse des processeurs ne suit pas aussi rapidement l'augmentation de la densité électronique. Entre 1997 et 2007 par exemple, les processeurs sont devenus 24 fois plus gros mais ils fonctionnaient seulement 10 fois plus vite (400 MHz à 4 GHz).
Un algorithme séquentiel, dans lequel une action est exécutée avant la suivante, voit sa vitesse d'exécution suivre la vitesse du processeur. Sa progression va donc s'accroître 10 fois sur la même période parce qu'il ne peut tirer avantage que de la vitesse réelle du processeur et aucunement du matériel complémentaire telle que l'accroissement de la densité des processeurs. En revanche, un algorithme parallèle peut distribuer le traitement entre unités. Ce traitement parallèle ne perturbe en rien l'efficacité du système. Un tel algorithme accroît la vitesse de traitement proportionnellement à la densité du processeur ainsi que de sa vitesse. Ainsi, si nous utilisons 100 fois plus de processeurs, chacun ne fut-ce que 2 fois plus rapide, nous obtenons une vitesse 1000 fois plus rapide et de 4 GHz nous passons à ... 4 THz ! La plupart des algorithmes consistent en un système à la fois série et parallèle. Si vous essayez d'installer plus de cartes processeurs pour faire tourner l'application plus rapidement, la partie série deviendra finalement le facteur limitatif du système. Vous allez pouvoir augmenter la vitesse de la partie parallèle de l'application, mais pas la partie série qui formera le goulot d'étranglement du système. C'est le maillon le plus faible et donc la partie série de l'algorithme qui détermine en dernier ressort votre vitesse maximale d'exécution. Pour exploiter des systèmes distribués ainsi qu'on appelle ces systèmes informatiques tel SETI@home ou Einstein@Home, les programmeurs doivent donc développer des algorithmes utilisant une très petite partie série mais une énorme fraction du système fonctionnant en mode parallèle. La partie série est souvent réduite aux entrées et sorties de données bien qu'ici encore les coûts des traitements et des composants diminuant, on peut envisager un traitement totalement parallèle avec de larges bandes passantes. Ainsi que le montre bien le graphique présenté un peu plus bas à droite, le nombre de canaux analysés par les programmes SETI suit la loi de Moore depuis Ozma en 1960. Etant donné que les algorithmes des applications distribuées s'adaptent facilement au traitement parallèle, il ne fait aucun doute que ce genre d'applications continuera à tirer avantage de la puissance des ordinateurs mis en parallèle ainsi que nous le promet la loi de Moore. Une conséquence économique La loi de Moore est une conséquence de l'évolution économique et non pas une loi de la physique. La taille du processeur à laquelle la loi de réfère est la dimension du plus grand chip commercialement disponible, non pas celle du plus grand qui puisse être produit en laboratoire où le coût n'est pas pris en considération. Aussi, pour poursuivre sa croissance, la physique doit supporter les besoins de la communauté. Mais comme en chimie, les ingénieurs sont en retard sur la pratique et nous devons souvent marquer le pas de quelques cycles d'horloges en attendant que le nouvel ordinateur sorte sur le marché. Le problème vient du fait que les constructeurs doivent toujours améliorer leur haute technologie pour élaborer des appareils plus puissants, plus compacts, à prix constant. C'est pour cette raison que tous les trois ans environ vous pouvez acheter un nouvel ordinateur pour le même prix que votre ancien mais il sera au moins deux fois plus puissant, plus complet et peut-être même plus compact et équipés de moyens multimédia ignorés jusqu'alors. Du point de vue de la physique, pour poursuivre cette croissance nous avons besoin de composants plus petits et donc assemblés sur une surface plus denses, plus puissants, mais tout aussi fiables. Apparemment ce n'est pas un problème car ces composants fonctionnent en général très bien en laboratoire. Comme on le sait les pannes, les "blue screen" et autres "bombes" n'apparaissent qu'une fois le produit commercialisé et lors des démonstrations publiques, Bill Gates en ayant lui-même fait la désagréable expérience !
Les barrières qui s'opposent à ce progrès sont économiques et liées au développement. Des investissements très onéreux doivent être consentis pour développer de gros processeurs qui seront par la suite économiques à fabriquer. Le consensus s'établit en raison de l'énorme taille du marché électronique mondial (environ 10 mille milliards de dollars par an) et le développement suit automatiquement. Le reste est une question de politique commerciale et de marketing. L'impact de la loi de Moore sur les projets Les constructeurs ainsi que les scientifiques doivent également tenir compte de la loi de Moore lorsqu'ils élaborent un projet à long terme car cela a des implications directes sur les coûts de production et les performances du système. En effet, quand on conçoit un produit, il est difficile d'entrevoir le futur et un chef d'entreprise ne peut pas patienter indéfiniment sans risquer de perdre son marché. Le chef de projet doit donc bien arrêter un jour ou l'autre la phase préliminaire de veille et de préanalyse tout en utilisant la technologie la plus récente. Seul désavantage, deux, cinq ou dix ans plus tard, lorsque le projet est enfin finalisé et mis en production, la technologie est déjà dépassée... Seule solution, créer un appareil modulaire, scalable, dont les différents éléments sont facilement remplaçables par de plus performants tout en gardant une compatibilité "downward" si nécessaire. Mais cela n'est pas toujours possible.
Tous les responsables de produits et autres maîtres d'oeuvres connaissent très bien ce dilemme : le produit qu'ils viennent de mettre au point utilise une technologie parfois inventée... il y a plus de 10 ans, lorsque l'idée du projet fut émise pour la première fois. Aussi, le jour où le produit est enfin opérationnel, on constate que la concurrence et même les amateurs, toujours à la pointe du progrès, disposent parfois de systèmes plus performants ! Dans le pire des cas, le produit est un échec et retiré du marché moins d'un an plus tard. Ce n'est donc pas sans raison que les leaders du marché de l'électronique et de l'informatique tels qu'Intel et ATI/AMD, NVidia et Matrox, Apple, Samsung et LG ou encore Lenovo et HP se font une guerre commerciale sans répit ni merci car celui qui perd un marché qui se chiffre en millions d'articles chaque année, perd une bonne partie de ses revenus. On peut réduire cet délai entre le concept et le produit fini en développant plus rapidement le produit, ce qui demande généralement plus de ressources, ou en réduisant ses fonctionnalités pour les développer plus tard. Mais cela ajoute autant de nouveaux risques potentiels (en terme de personnel, de budget et autres ressources disponibles), qu'il faut pouvoir gérer dans le temps au risque de développer un produit peu performant voire ne répondant pas du tout au cahier des charges du client. Nous avons des exemples de tels écarts entre le projet initial et le produit final avec les grands projets européens (Eurotunnel, Galileo, etc) qui ont pris énormément de retard et englouti beaucoup plus d'argent que prévu. On peut aussi citer les projets de la NASA et de ses contractants, a priori constitués d'experts maîtrisant ces risques. Ainsi, le système de transmission des sondes spatiales Pioneer 10 et 11 lancées en 1973 vers Jupiter présentait un débit à peine supérieur à celui des premiers modems existants à cette époque (16 à 2048 bits/s) ou le système optique du Télescope Spatial Hubble (HST) dont la qualité des images était tellement mauvaise qu'il fallut programmer plusieurs missions de maintenance pour corriger ses défauts. Dans l'industrie, deux tiers des projets échouent faute d'une bonne gouvernance. Nous avons des exemples avec quantité de produits informatiques et autres gadgets qui ont été commercialisés en espérant devenir incontournables mais qui n'ont trouvé aucun marché. Pour une entreprise financièrement fragile, les investissements perdus en recherche et développement et la perte de réputation peuvent conduire à sa faillite. Ces exemples montrent clairement que la loi de Moore n'est pas une invention de la nature mais une représentation de la manière dont notre société appréhende le futur. L'informatique distribuée Un exemple d'impact de la loi de Moore sur les projets est l'évolution des réseaux informatiques qui est étroitement liée à celle des ordinateurs. Quelques grands projets tel que l'analyse cryptographique, l'étude génétique, la recherche contre le cancer, les prévisions météorologiques, l'étude des changements climatiques, etc., tirent aujourd'hui avantage du traitement parallèle pour résoudre ces questions. Pour résoudre ces problèmes encore plus rapidement, on inventa l'informatique distribuée : les programmes sollicitent l'aide de centaines et de milliers de machines d'utilisateurs connectés à Internet dont les ordinateurs sont en veille ou du moins dont le temps CPU ou GPU est sous-exploité.
Pour déterminer si le type d'ordinateur peut-être utilisé dans le cadre d'un programme distribué, nous devons répondre à trois questions : - Les algorithmes permettent-ils un traitement distribué ? Oui, et ils sont hautement parallèles - Les ressources informatiques sont-elles disponibles ? Oui, le programme permet à des particuliers de dédier les cycles de veille de leur ordinateur au projet. - Quelle est la puissance de calcul ou de traitement d'un système distribué ? SETI@home représente une puissance de calcul supérieure à 637 TFLOPS en 2013, bien supérieure à celle de beaucoup de superordinateurs. Si une unité de travail traite une bande de fréquence large de 100 kHz, avec 100000 utilisateurs actifs cela représente une bande passante de 10 GHz traitée en quelques heures. - Ce réseau peut-il supporter la bande passante requise ? En l'an 2000 Internet était assez limité. Prenons l'exemple du plus grand système de télécommunication au monde en dehors du réseau Echelon de la NSA, le radiotélescope d'Arecibo. Supporter par exemple une bande passante de 60 GHz nécessiterait un radiotélescope qui, connecté à Internet devrait gérer un échantillonnage de 80 milliards de données par seconde. C'est environ 10 ordres de grandeur plus rapide que la connexion Internet d'Arecibo. On ne peut donc pas travailler ainsi. C'est pourquoi un programme basé sur des calculs distribués mais offrant une capacité d'entrée/sortie limitée (celle de votre connexion par modem, ADSL ou en fibre optique variant entre 56 Kbits/s et 100 Mbits/s) doit transférer ses données traitées localement sur des disques durs des serveurs du centre scientifique, dans ce cas-ci à l'Université de Berkeley qui effectuera les analyses complémentaires. La puissance de traitement étant aujourd'hui disponible et les réseaux informatiques de plus en plus à haut débit ayant transformé la planète en un village global, la technologie informatique est devenue plus fiable et plus simple à utiliser. Il ne fait aucun doute qu'à l'avenir une quantité croissante de projets en tireront avantage. Jusqu'où peut aller la loi de Moore ? Combien de temps cette tendance peut-elle continuer ? On disait que la loi de Moore continuerait certainement d'être valide jusqu'en 2020. Mais rassurez-vous, ensuite toutes les sociétés, tous les chercheurs et tous les amateurs utilisant du matériel électronique ou informatiquetireront encore profit quelques années des technologies inventées 10 ou 20 ans plus tôt. Autrement dit, la population voire même les administrations peuvent facilement avoir 20 ans de retard sur certaines nouvelles technologies qui resteront longtemps hors de prix. Suivant la loi de Moore, l'évolution technologique a progressé de façon constante au cours des dernières décennies. Cela concerne autant les micro-ordinateurs que les superordinateurs. Ainsi, en 2004 soit 23 ans après le premier PC, le processeur le plus rapide équipant un micro-ordinateur était cadencé à 3.8 GHz (Intel Pentium A et D). L'ordinateur le moins cher pouvant l'utiliser revenait à environ 1000 €, soit 3 à 4 fois moins cher qu'il y a une génération pour des performances mille fois supérieures !
Par comparaison, en 2004 le superordinateur le plus rapide était le NEC SX-8 capable d'effectuer 65 mille milliards d'opérations par seconde, ce qui représente une puissance de calcul de 65 TFLOPS. Le SX-8R fut notamment loué pour 3.8 millions d'euros/an à Météo-France pour le modèle Arome. Le SX-8 fut également utilisé par le CEA et l'Académie des Sciences et Humanités de Bavière (LRZ). Mais en 2010, ce superodinateur n'était déjà plus listé dans le TOP500 des superordinateurs les plus rapides, replacé par le NEC SX-9 et bien d'autres beaucoup plus performants. En 2013, le Cray XC30 de la NSA dépassa 100 PFLOPS et Cray (aujourd'hui HPE) fabriqua un modèle de 1 exaFLOPS en 2018. En 2023, la NNSA (National Nuclear Security Administration) et le LLNL (Lawrence Livermore National Laboratory) disposeront du superordinateur El Capitan de HPE (qui racheta Cray en 2019) présenté à gauche qui atteindra 2000 PFLOPS (crête) soit 2 exaFLOPS. Peut-on aller plus loin et à quel prix ? En fait, comme la loi de Moore l'indique, tout système électronique ou informatique est déjà dépassé dès qu'il est mis en production. Cette question économique qui touche à l'obsolescence de tous les produits intéresse énormément de personnes dont la société Sematech par exemple, constructeur de processeurs qui rédiga en 1997 un rapport sur l'état de la technologie électronique et son évolution au cours des 15 années à venir. L'étude de Sematech prenait en considération toutes les phases du développement telles que les ressources, la conception, les tests, l'intégration, le traitement, la lithographie, l'interconnexion, l'assemblage, le packaging, l'environnement, la réduction des défauts, la métrologie, la modélisation ou les simulations.
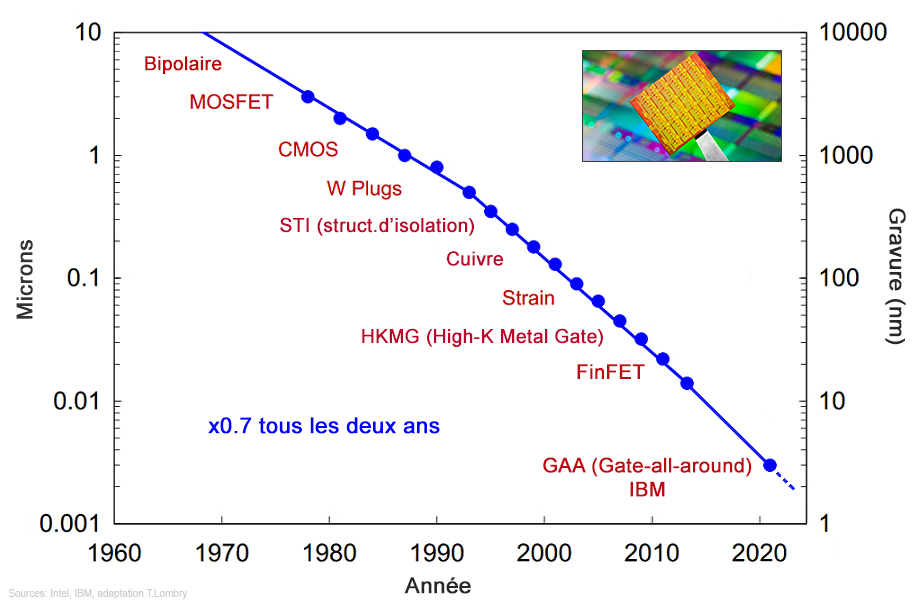
Sematech prédit que la loi de Moore progresserait jusqu'en 2012, le terme de son étude. Sur base des connaissances actuelles et de discussions avec plus de 300 experts, le physicien et futurologue Michio Kaku a projeté cette loi jusqu'en 2020 avec de fortes certitudes. On reparlera de cette extrapolation réaliste quand nous aborderons les technologies du futur. Finalement, on a constaté que la loi de Moore s'est arrêtée brutalement, d'abord en termes d'économie en 2015 et à présent en termes de taille physique des microprocesseurs à base de silicium. A la densité estimée des composants (1.4 milliard de transistors dans un processeur Intel Core en 2012), en 2016 on parlait de nanotechnologique avec des processeurs élaborés avec une technologie de gravure de 10 nm soit 22 fois supérieure qu'en 2000. Comme nous l'avons expliqué, en 2021 IBM réussit à graver des processeurs en technologie de 2 nm. Il sera difficile de dépasser la limite du nanomètre. En effet, à cette échelle la physique actuellement utilisée ne fonctionne plus aussi bien car les effets quantiques commencent à dominer sur les processus. Les scientifiques recherchent donc de nouvelles façons de continuer à augmenter les performances des microprocesseurs sans avoir à compter sur le rétrécissement. des transistors. L'une des voies explorées consiste à tirer profit de transistors CNFET (Carbon Nanotube Field-Effect Transistor) en graphène placés sur un chip à quatre couches comprenant également la mémoire RRAM. Les premiers essais montrent qu'on peut y placer des millions de transistors (cf. MIT, IEEE et Silverton Consulting). Pour la fin de la décennie 2020, l'évolution est moins claire car la technologie utilisera des composants qui sont aujourd'hui à l'état de concepts et de prototypes (transistors CNFET, optiques, systèmes photoniques, etc). Toutefois, les mêmes effets quantiques permettront d'élaborer de nouveaux appareils plus petits assurant les mêmes fonctions et qui seront encore plus performants. A ce moment là nous seront toujours quelques ordres de grandeur au-dessus des limites physiques apparentes de ces composants, qui peuvent par exemple se limiter à... un seul électron ! La Singularité Technologique Lorsque la loi de Moore est présentée en coordonnées semilogarithmiques, comme Moore la présenta originellement et que nous la représentons habituellement, elle n'a rien d'extraordinaire - c'est une courbe plus ou moins positive - et on peut même la trouver banale. Mais si vous la tracez linéairement, plus en rapport avec notre expérience humaine, la loi de Moore tend vers la Singularité Technologique. Elle démarre en haut à gauche avec le premier ordinateur et le premier microprocesseur et termine sa course en dessous à droite de manière asymptotique avec une profusion d'ordinateurs et de processeurs, butant finalement sur le cadre. Qu'est-ce que cela signifie ? En matière d'électronique on constate qu'il y a 50 ans, les nouveautés étaient ponctuelles, parfois prévisibles et on les exploitait pendant 5 ans sinon davantage. Aujourd'hui, beaucoup de fabricants construisent des processeurs et des circuits intégrés et les nouveaux produits sont de plus en plus nombreux et toujours plus performants. Le délai d'une nouveauté à l'autre s'accélère de façon exponentielle.
En 2008, dans le webzine "IEEE Spectrum", plusieurs auteurs déclarèrent que nous pourrions atteindre la Singularité Technologique d'ici 30 ans et que sera peut-être à cette époque que les robots auront l'intelligence des hommes, cette dernière affirmation étant plus douteuse. En d'autres termes, la loi de Moore pourrait s'infléchir et connaître un plateau entre 2020 et 2030. Certains experts estiment toutefois que nous n'atteindrons pas la Singularité avant 30 à 70 ans voire jamais. Pour sa part, Gordon Moore pense que la Singularité ne surviendra jamais. Pour renforcer l'idée de Moore, rappelons que le même principe de singularité s'applique à beaucoup d'autres domaines. Ainsi l'évolution de la vie fut très lente durant plus de trois millards d'années avant d'exploser dans une profusion d'espèces sans conduire à l'extinction de la vie, que du contraire; la Terre a compté 100 milliards d'espèces ! On peut également citer les changements de paradigmes qui sont de plus en plus nombreux et sans lesquels il n'y aurait pas de révolutions intellectuelles. Enfin, le coût du séquence de l'ADN a diminué de façon exponentielle au cours des vingt dernières années. La conséquence de ces changements de plus en plus fréquents et importants est que l'homme est aujourd'hui incapable de prédire les tendances technologiques à plus d'une génération voire même dans un délai de 15 ans. Ainsi, même les "Visions" (1997) du physicien et futurologue Michio Kaku se sont avérées fausses à l'exception du réseau informatique global (mais à l'époque de sa rédaction, Internet existait déjà). Ainsi que nous le verrons à propos des technologies du futur, cette incapacité à prédire l'avenir au-delà de 15 à 25 ans signifie que l'homme est en train de perdre son "pouvoir de prédestination" au profit des machines. Cette vision pessimiste d'un avenir mécanique et robotisé qui ne laisse plus de place à l'homme ni aux sentiments est le risque que nous courrons si nous ne gardons pas le contrôle de nos inventions et de la vision de notre avenir. Cette philosophie que les auteurs de science-fiction appellent la "Black Tech" a notamment donné quelques oeuvres d'anthologie dont "I, Robot" (Isaac Asimov, 1978), "Blade Runner" (Philip K. Dick, 1982), "Planète Hurlante" (Philip K. Dick, 1995) ou encore "A.I." (Steven Speilberg, 2001) parmi d'autres. Nous reviendrons sur cette philosophie à propos des robots notamment. Plus loin que la loi de Moore Notons que Paolo Gargini, directeur de la stratégie technologique chez Intel a envisagé en 2016 d'abandonner la loi de Moore lorsqu'on atteindra le seuil des 2-3 nanomètres et des composants de la taille de 10 atomes, c'est-à-dire vers 2020. Il suggère de suivre "More than Moore' strategy", plus que la stratégie de Moore : plutôt que d'améliorer les processeurs et laisser les applications vivre, Gargini propose d'abord de s'occuper des applications au sens large, des smartphones aux superordinateurs en passant par les data centers du Cloud et d'évaluer quels genres de processeurs nous aurons besoin pour soutenir cette croissance. Parmi ces processeurs, il y aura des capteurs de nouvelle génération, des circuits de gestion de l'énergie et d'autres dispositifs exigés par des systèmes de calculs de plus en plus mobiles. Pour sa part, l'Association de l'Industrie des Semiconducteurs (SIA) alla dans le même en 2016 dans son rapport "Rebooting the IT Revolution: A Call to Action". En effet, la SIA évoque un "bloquage technologique" et une perte de leadership pour les Etats-Unis si les grands argentiers (NSF, NIST, DARPA, DOE, etc) ne libèrent pas rapidement des fonds pour développer des innovations qui relanceront le progrès (par exemple en nanotechnologie, télécommunications, stockage de l'information, sécurité, systèmes scalables, informatique quantique, etc., ainsi que dans les autres secteurs et notamment en neurosciences, en médecine, en biologie, en génie génétique, en aéronautique, en efficacité énergétique, en développement durable, etc.) La loi de Neilsen Un autre exemple de croissance constante est connue sous la loi de Neilsen de la bande passante d'Internet. Dans les années 1970 nous utilisions des modems asynchrones de 1200 bauds (bits/s) puis de 2400 bits/s et finalement de 33.6 Kbits/s, jugés très rapides.
A la fin des années 1980 le modem de 56 K était le standard mais il s'avéra rapidement trop lent pour un usage intensif des BBS et autres WAN. Aussi vers l'an 2000 la connexion permanente ADSL inventée deux ans plus tôt fut disponible dans la plupart des foyers connectés à Internet. Les coûts étaient réduits et la rapidité de 512 Kbits/s à 10 Mbits/s (même 24 Mbits/s en 2008 grâce à l'ADSL2+) suffisante pour télécharger des images ou des vidéos ainsi que pour établir des liaisons continues en "streaming" audio ou vidéo. Mais de nouveau, progrès et demande du public obligent, en quelques années ce débit est devenu trop lent pour véhiculer des vidéos en définition HD et télécharger des fichiers de plusieurs centaines de megabytes. Aussi, depuis 2010, les liaisons par fibre optique se sont généralisées y compris chez les particuliers. Les débits fixés par les autorités varient entre 10 et 100 Mbits/s mais les cartes réseaux peuvent supporter 1 Gbits/s, ce qui aussi la limite de l'ADSL2, y compris sur les mobiles en 4G (en voie descendante ou downstream). Les pertes sont très faibles avec une atténuation de ~ 0.15 dB/km à 1570 nm. Le débit record est de 1 petabit/s sur une distance de 52.4 km. Il fut établi en 2012 par NEC et Corning. La loi de Neilsen stipule que les connexions à hauts débits doublent tous les 21 mois (plus lentement que la loi de Moore). Toutefois cette amélioration ne pourra pas tout de suite être appliquée chez les particuliers car l'infrastructure physique et les serveurs d'accès doivent d'abord être mis à jour pour supporter cette cadence. En planifiant la prochaine génération de systèmes, les utilisateurs doivent garder le contrôle de toutes les ressources et des connexions qu'ils utilisent. Cela permettra à chacun d'optimiser les bénéfices qu'il retire des facteurs de cette croissance exponentielle. Pour plus d'informations Evolution des chips Intel (poster PDF), Intel TOP500 des superordinateurs Rebooting the IT Revolution: A Call to Action, SIA, 2016 The chips are down for Moore's Law (fin de la loi de Moore selon l'industrie des semiconducteurs), Nature, 2016 The Lives and Death of Moore's Law, Ilkka Tuomi/First Monday, 7, 11, 7 Jan 2002 Moore's Law, Intel Cramming more components onto integrated circuits (PDF, la loi de Moore), G.Moore, Electronics, 38, 8, 1965.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}