|
|
|
Le Big Data et le data mining
Le monde digital en chiffres (I) Qu'est-ce que le "Big Data", mis à part un terme aujourd'hui à la mode, comment le gère-t-on et dans quel but ? Quand on évoque le concept de Big Data, on pense naturellement à la gestion de gros volumes de données. Au cours de la conférence sur la "Technonomie" qui s'est tenue à Lake Tahoue en 2010, Eric Schmidt, CEO de Google avait déclaré : "Nous avons créé 5 exabytes d'informations depuis l'aube de la civilisation jusqu'en 2003. Nous en créons autant tous les deux jours et ce taux augmente." Nous verrons que les infrastructures de Google, Yahoo!, YouTube, du CERN ou de la NSA nous en apportant des exemples concrets; ils gèrent des installations hardware qui s'étendent sur 10000 m2 à 100000 m2 ! C'est tout un quartier qui est réservé au stockage et au traitement des informations ! Ceci illustre la question cruciale qui intéresse tous les scientifiques et économistes du monde : comment faire face à de telles quantités de données ? Faute d'information, pour la majorité des décideurs d'entreprises (plus de 80% en 2012 selon IDC), c'est encore une inconnue ou le synonyme de problème à résoudre, de problème d'analyse, de problème de stockage et de nouveaux "problèmes". Bref, pour beaucoup c'est une excuse pour ne pas relever le défi. La plupart des décideurs n'imaginent pas encore qu'une bonne gestion du Big Data peut apporter des solutions et offrir des opportunités, est synonyme de simplification, de précision, de rapidité, d'optimisation, d'amélioration, bref un avantage concurrentiel.
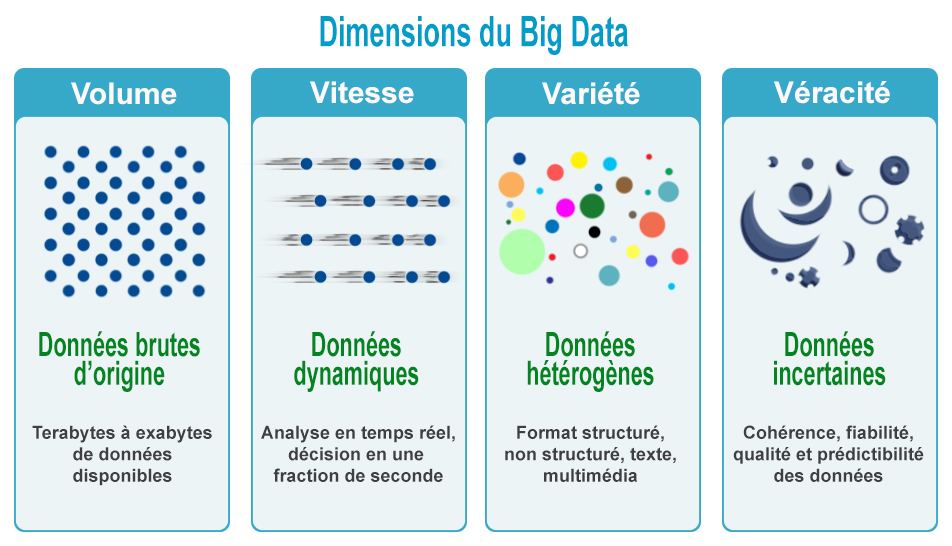
Définition Comme le disait Paul Doscher, CEO de LucidWorks, une société experte en solutions analytiques : "Le Big Data ce n'est pas un plus grand data warehouse". Autrement dit, exploiter le Big Data ne consiste pas à construire des data centers toujours plus grands pour stocker toujours plus de données. Le Big Data c'est bien plus que de la volumétrie. Nous allons affiner cette définition et en la précisant nous allons mieux comprendre son utilité. En effet, la volumétrie est une quantité relative qui dépend du secteur d'activité, de la taille de l'entreprise et de ses objectifs, bref du rythme du métier et du cycle de vie des données. Prenons quelques exemples. Pour une société de marketing, proposer une offre ciblée est plus important que de traiter l'information en temps réel ou en une fraction de seconde. En revanche, une société du secteur financier, un voyagiste ou un centre scientifique insistera sur la vitesse d'exécution et le service qu'il offre à ses clients en temps réel. On en conclut que selon le secteur d'activité, ce n'est pas nécessairement le volume des données qui est important mais parfois d'autres critères ou leur combinaison. De manière générale on définit un "Big Data" comme tout critère, dimension ou attribut qui défie les contraintes de capacité d'un système ou d'un besoin métier et qui va donc au-delà de ce qu'on peut normalement gérer ou réaliser. L'univers multi-dimensionnel du Big Data En 2001, dans un rapport du Groupe META (futur Gartner Group), Doug Laney décrivit les nouveaux enjeux liés à la croissance de ce qu'on appellera par la suite le Big Data dans un modèle articulé autour de 3 attributs représentés par les "3 V" : volume, vitesse et variété. Ce modèle toujours d'actualité fut complété par IBM qui ajouta un quatrième V, la véracité. Plus récemment, quatre nouvelles dimensions pertinentes ont été ajoutées : la valeur, la visibilité, la datavisualisation et les opportunités. Le modèle Big Data est aujourd'hui défini par 8 attributs : - Des volumes importants de données stockées ou présentes à un instant donné et qu'il faut capturer (en terme de flux). Concrètement, pour une boutique en ligne, une entreprise de marketing ou un laboratoire de recherche, il est souvent nécessaire de disposer d'un grand nombre de données pour disposer d'un échantillon représentatif de la réalité et mener à bien les études ou les recherches. Un commercial sera très heureux de pouvoir disposer de 10 ou 100 millions d'enregistrements afin d'identifier les clients potentiels. Un département se consacrant à l'étude des sciences de la terre ou du ciel exploite plusieurs centaines de millions voire des milliards d'enregistrements. - La vitesse d'exécution d'enregistrement, d'analyse et de prise de décision. Le temps de capture des données, d'exécution des requêtes et des traitements doivent correspondre au cycle de vie des données et aux besoins du métier, notamment aux attentes des clients qui souhaitent généralement une réponse ou une information en temps réel ou légèrement différée et même parfois proactive. Ainsi, une agence de renseignements ou un bureau d'enquête analysera volontiers un fichier de 500 millions de transactions quotidiennement pour y déceler les fraudes éventuelles. Plusieurs fois par jour, une banque d'affaire doit pouvoir envoyer les centaines de milliers de rapports financiers à ses clients en moins d'une heure. En revanche, si un phénomène évolue rapidement dans le temps, un laboratoire de génie génétique ou de microbiologie doit disposer des résultats d'une analyse de millions d'échantillons en moins de 2 minutes ou les suivre en temps réel. - La variété ou l'hétérogénéïté des données, des supports et des formats. Les données proviennent de sources internes ou externes dont les supports et les formats ne sont pas toujours contrôlés par l'entreprise. Le format des données stockées dans une base de données est différent de celui d'une feuille Excel, des pages html, des e-mails, des petites annonces, des SMS ou des vidéos. Les capteurs, les émissions radios, les photographies, les dessins et les films utilisent leur propres structures de données. Ces données structurées, semi-structurées ou non structurées doivent être exploitées dans leur format natif. La disponibilité des données étant un facteur essentiel pour les besoins du métier et donc la pérénité de l'entreprise, nous y reviendrons dans un instant.
- La véracité des données, c'est-à-dire leur fiabilité et leur qualité. Proposée par IBM, cette dimension est essentielle car de plus en plus de données proviennent de sources extérieures, hors du périmètre de contrôle de l'entreprise. Il est stratégique pour sa pérennité et sa réputation ques les données proviennent de sources fiables. Comme la rumeur propage de fausses informations, de fausses données génèrent de faux résultats. - Les valeurs que représentent ces données apportent de nouvelles connaissances. L'analyse des données donne du sens aux informations collectées, à la fois individuellement en isolant l'épiphénomène et globalement. Ainsi, la surveillance d'un réseau de milliers de caméras de surveillance permet de contrôler les zones suspectes qui, allié à un système de reconnaissance de forme permet d'identifier les suspects. Une gestion globale des tremblements de terre ou de l'activité volcanique à travers le monde grâce aux satellites radars et balises GPS permet d'évaluer avec précision l'évolution d'évènement imperceptibles depuis le sol ou étudiés manuellement et permet d'anticiper des cataclysmes et de prévenir les populations concernées. - La visibilité des données à travers des tableaux récapitulatifs ou dashboards. Disposer de données mais ne pas pouvoir s'en servir ou les visualiser est une perte de temps et d'argent. Il est nécessaire que les informations soient factuelles, disponibles et visuellement présentables, c'est-à-dire accessibles rapidement afin de les surveiller, de les comprendre quel que soit le support utilisé. Les dashboards sont généralement utilisés par les managers, chefs de projets et autres dirigeants des entreprises ainsi que par les équipes marketing qui ont peu de temps pour pour prendre une décision et de ce fait ont besoin d'une interface optimisée et intuitive (par ex. CaptainDash). - La datavisualisation concerne la représentation des données sous formes intelligentes, pratiques et interactives. Il n'est rien de plus pénible que de devoir lire un texte ou un tableau de nombres si on peut le résumer par un graphique. Le Big Data s'adapte parfaitement à l'expression "une image vaut mille mots". Si l'exploitation des données permet de leur donner du sens, ce sont les images, les diagrammes, les graphiques, les cartes et les infographies qui leur donne un sens global, révèle les points forts et les détails. En éliminant les requêtes, en simplifiant les analyses, grâce à une interface interactive (par ex. Webmasters), les visuels apportent une réponse rapide, améliorent la qualité de l'aide à décision, accélèrent la prise de décision et offrent plus de liberté aux utilisateurs pour développer leur créativité. - Les opportunités offertes par la gestion de ces données en terme d'économie d'échelle et de métier. Tirer avantage des opportunités peut faire évoluer la stratégie de l'entreprise, augmenter sa compétitivité et améliorer sa réputation. Sur les plans technique et financier, les coûts d'installation et d'exploitation d'un réseau d'ordinateurs sont inférieurs à ceux d'une seule infrastructure équivalente, les traitements étant également répartis sur plusieurs "petites" machines. Point de vue métier, le client possède des données que les autres ne possèdent pas, lui offrant un avantage sur ses concurrents. Il peut également tirer parti ou monnayer ses connaissances et ses services, les distribuer et améliorer la satisfaction de ses clients. A propos de la variété des données Les données représentent la matière première de l'entreprise mais avant de les exploiter il faut savoir où les trouver en fonction des besoins du métier. On peut regrouper les sources de données en 6 grandes catégories : - Les outils professionnels comprenant les logiciels et services des entreprises. Il s'agit des logiciels de gestion (Customer Relationship Management, Enterprise Resource Planning, Supply Chain Management, etc), les outils de production de contenu et les suites bureautiques telles que MS-Office et autre suites Adobe. Selon Microsoft, la moitié des données produites par la suite Office sont hors contrôle et ne sont donc pas valorisées. Le meilleur exemple est le courrier électronique avec ses plus de 100 millions d'e-mails envoyés chaque minute.
- Internet et ses volumes gigantesques de données stockées dans les sites d'actualités, scientifiques, gouvernementaux, de commerce en ligne, des entreprises, des organisations et des amateurs. Ces ensembles hétéroclites génèrent des interactions de plus en plus nombreuses, rendant les annuaires et moteurs de recherche indispensables, eux-mêmes étant une source de données grâce aux requêtes des internautes. - Les réseaux sociaux. Bien qu'accessibles via Internet, ils constituent une source distincte de données car ils proposent aux internautes de nouveaux outils d'expression. Le Web 2.0 en particulier permet à chacun d'interagir et de collaborer sur le web dans le but de produire du contenu pour une communauté virtuelle. C'est valable pour les grands réseaux sociaux tels que Facebook ou YouTube mais également pour les sites de partage tels Flickr ou Instagram, les blogs, les flux RSS, les réseaux professionnels tels LinkedIn, Yammer, etc. Chaque seconde se sont des mégabytes de données qui sont publiés sur ces sites depuis pratiquement tous les points du globe. - Les systèmes connectés. Pour une entreprise analysant le Big Data, un smartphone ou un ordinateur disposant d'une connexion Internet n'est pas un terminal mais une source de données, et la NSA le sait mieux que quiconque. En moyenne, un internaute établit 150 connexions par jour via son smartphone pour consulter ses messages, se connecter aux réseaux sociaux et autres services en ligne. A l'avenir l'Internet des Objets permettra aux entreprises de recueillir et d'analyser directement des données opérationnelles pour améliorer les services ou en développer de nouveaux. - Les données structurées. Il s'agit des données stockées par rangées et colonnes dans des bases de données et généralement exploitées par les entreprises (comptabilité, finance, gestion de stock, ressources humaines, recherche scientifiques, bases documentaire, etc.) - Les données non structurées. Il s'agit des donnés produites par les outils les plus divers allant des logiciels bureautiques aux articles publiés sur les blogs ou les messages diffusés sur les forums. Ils ne sont pas organisés, les formats variés et leur nombre augmente de manière exponentielle et sans contrôle, principalement via les réseaux sociaux et autres communautés virtuelles. C'est leur développement qui est à l'origine du Big Data. Le cadre étant défini, intéressons-nous à la volumétrie que traitent aujourd'hui les data centers, c'est-à-dire les infrastructures qui stockent et traitent ces données. Volumétrie des données Dans une étude publiée par la Commission Européenne en 2015 et reliée par l'IUCN, on apprend que dans le monde on a créé plus de données en 10 minutes qu'au cours de toute l'histoire de l'humanité jusqu'en 2003 ! Et pourtant les grandes bibliothèques comme les médiathèques numériques sont vastes ! Dans les années 1990, quand nous effectuions une recherche sur Internet, nous étions ravis quand nous trouvions une bribe d'information. Aujourd'hui nous sommes étonnés quand nous ne trouvons pas au moins une page d'hyperliens et déçus quand il n'y a pas la moindre image ! Dans un article publié en 2009 dans le Times et repris par Google, on apprenait que les internautes avaient effectué 100 milliards de recherches sur Internet (ce qui engendrait par ailleurs 8400 tonnes d'émission de gaz à effet de serre chaque une année !). Début 2013, on a dépassé le nombre de 200 milliards de requêtes par mois, ce qui représente plus de 77000 requêtes par seconde ! En 2014, Google avait indexé plus de 30000 milliards de pages, ce qui représente 100 petabytes[1] de données selon Statistic Brain contre 462 milliards de pages pour Archive. Mais toutes ces données ne représentent qu'une goutte d'eau quand on sait qu'en 2014 le web contenait 200 millions de fois plus d'information ! Pour gérer ce flux astronomique de données, Google a installé 36 data centers à travers le monde, chaque site comprenant plus de 25000 serveurs et des dizaines de milliers de disques durs disposés dans des racks que l'on peut remplacer à chaud (hot swappable). Ici le "Big Data" prend tout leur sens ! Selon Alexa, en 2016 Google demeure le site web le plus fréquenté dans le monde.
A voir : Explore a Google data center with Street View A lire : Un Web plus respectueux de l'environnement, Google
Google n'est bien sûr pas la seule entreprise à disposer de data centers. Des constructeurs comme IBM, Intel, General Electric, HP, Unisys, Bull, Apple, des centres de recherches comme le CNRS, le CERN, le JPL, des sociétés d'assurances et des sociétés de service comme Facebook disposent de data centers; ces infrastructures sont devenues indispensables pour gérer les millions de documents et les milliards d'informations qu'ils traitent quotidiennement. Les données sont aussi représentées par les applications qui les exploitent car elles génèrent elles-mêmes de nouvelles données. Fin 2013, Google Play et l'Apple Store avaient dépassé les 50 milliards d'applications téléchargées. Selon une étude d'IDC, à l'échelle mondiale (sur le web, dans les entreprises, dans les centres de recherches, etc), en 2005 l'univers digital contenait 130 exabytes de données. En 2009, Internet avait accumulé 487 milliards de gigabytes de données soit 487000 petabytes ou encore 487 exabytes. Cela représente près de 0.5 zettabytes de données, l'équivalent de 60 fois la quantité d'information qu'on pouvait enregistrer sur tous les disques durs produits en un an dans le monde ! Si toutes ces données étaient imprimées dans des livres, ils formeraient une pile qui s'étendrait 10 fois sur la distance Terre-Pluton ! En 2012, nous avions créé dans le monde 2.8 zettabytes de données et nous devrions produire 40 zettabytes de données en 2020, soit 300 plus qu'en 2005 ![3]. Sur bases des données fournies par les opérateurs et les réseaux sociaux, on peut également chiffrer l'activité moyenne journalière sur le web. Ainsi, en 2012 YouTube enrichit sa vidéothèque d'une heure de vidéo (300 à 800 MB) toutes les secondes et 30 GB de données étaient créées sur le web ! Toutes les minutes 217 nouveaux comptes ont été créés par les internautes mobiles. Chaque jour, Facebook a généré 10 TB de données, 550 millions d'utilisateurs se sont connectés au réseau social et 1 milliard de statuts ont été mis à jour quotidiennement. 145 milliards d'e-mails ont été échangés, 540 millions de SMS ont été envoyés et 400 millions de Tweets ont été envoyés via Tweeter chaque jour ! Le Big Data en science Dans le domaine scientifique, les centres de recherches accumulent également quotidiennement des volumes gigantesques de données sans pour autant atteindre les volumes d'entreprises privées comme Google.
En 2016, l'initiative "Breakthrough Listen" du programme SETI financée par le milliardaire Yuri Milne sera opérationnelle. Les infrastructures SETI seront en mesure d'analyser 10 milliards de canaux ou fréquences simultanément. Les ordinateurs accumuleront 10 GB de données par seconde, soit près de 864 TB par jour ! C'est 9 fois plus que les installations du CERN et 30 fois plus que la quantité de données accumulée chaque nuit par les télescopes VLT ! Un autre "Wow" ! En 2013 le JPL, leader de la robotique spatiale, avait archivé 700 TB de données chaque jour provenant des sondes spatiales (une seule image prise par la sonde Mars Reconnaissance Orbiter occupe 120 MB) et des hauts-lieux de l'astronomie comme le SKA. Cette dernière installation dédiée à la radioastronomie devrait générer un débit de données entre 10 et 500 terabytes/s d'ici 2020 ! Jusqu'à présent, que ce soit à l'institut SETI ou au JPL, ces données étaient stockées parfois plusieurs années (jusqu'à 10 ans pour SETI) faute de ressources, en attendant d'être analysées. Pour accéder à ces données, les programmeurs ont récemment développé de nouveaux algorithmes en open-source et des applications adaptées à ces flux gigantesques. Les chercheurs SETI peuvent dorénavant accéder à douze mille fois plus d'informations tandis que les chercheurs du JPL ont la possibilité d'interroger simultanément une multitude de catalogues, à l'image de ce que font déjà les astronomes dans le cadre des programmes de sondages de l'univers profond (SDSS). Précisons que les données de SETI et du JPL sont également accessibles au public. Une technologie similaire a été développée pour l'étude des séismes dans le cadre du projet QuakeSim de la NASA dont les données GPS se comptent également par milliards de points de coordonnées chaque jour. En 8 ans (2000-2008), le Sloan Sky Digital Survey (SDSS), le plus vaste programme d'observation astronomique, a enregistré 140 terabytes d'images. Il a permis aux astronomes d'étudier l'univers en 3D jusqu'à 1.3 milliards d'années et s'efforce actuellement de compléter ce sondage jusqu'aux limites de l'univers observable, soit plus de 13 milliards d'années-lumière. Avec ses 4 télescopes de 8.2 m installés au sommet du mont Paranal au Chili, le VLT (Very Large Telescope) enregistre 30 TB de données brutes chaque nuit qui sont ensuite transmises à l'ESO pour traitement. Même volumétrie pour le futur télescope LSST (Large Synoptic Survey Telescope) de 8.40 m de diamètre qui devrait être opérationnel en 2021 sur une montagne proche du Paranal. Vers 2024, lorsque le projet Petasky sera terminé, il aura récolté 140 petabytes de données contenant des centaines de caractéristiques pour chaque objet du ciel. Le VLT est complété par le "petit" télescope VST de 2.65 m de diamètre équipé d'une caméra CCD OmegaCAM de 368 megapixels qui enregistre 30 TB de données chaque année. A
voir : A Flight Through the Universe, by the Sloan Digital Sky Survey
Panorama des télescopes VLT installés au sommet du mont Paranal au Chili. Dans le secteur automobile, les nouveaux véhicules équipés d'un système de pilotage automatique par lidar (Google Car, BMW, Ford, etc) doivent gérer 3 millions d'informations par seconde afin de pouvoir réagir en temps réel même à grande vitesse. En physique des particules, le CERN est aussi concerné par le Big Data. En fait, c'est l'organisation scientifique civile la plus exigeante et la mieux équipée en ce domaine. Selon Tim Bell, responsable de l'infrastructure au CERN, le "Big Data Challenge" est de gérer les 35 petabytes de données générées chaque année par le LHC et qui devrait doubler après son upgrade à 14 TeV vers 2015. Lors d'une collision entre protons, la caméra de 100 megapixels du LHC enregistre 40 millions de photographies par seconde, générant 1 petabyte de données par seconde ! "Si ça ne sont pas des Big Data, je ne sais pas ce que c'est", a déclaré Bell lors de la conférence "Structure" sur les architectures informatiques qui s'est tenue à Londres en septembre 2013.
"Nous reconnaissons que notre défi n'est pas particulier - Google est loin devant nous en terme d'échelle. Nous devons construire ce qu'ils ont fait", a-t-il ajouté. Aucun superordinateur ne pouvant gérer seul la totalité des données du LHC, le CERN a développé un réseau de 260 sites informatiques distribué à travers le monde, le WorldWide LHC Computing Grid, dont le coeur ou Tier 0 est à Meyrin (Genève). Le Tier 0 exploite un data center constitué de 88000 coeurs de processeurs. Il stocke en ligne 30 petabytes de données sur disques durs et 70 petabytes sur tapes. Depuis 2014, le data center de Budapest en Hongrie dispose de 300 000 coeurs de processeurs Aujourd'hui, le CERN est capable de traiter des fichiers de données (data set) de 125 TB. Cette infrastructure est utilisée par plus de 11000 chercheurs dans le monde. Le Big Data selon la NSA Ainsi que nous l'avons expliqué dans l'article consacré à l'espionnage et l'affaire PRISM dévoilée en 2013, pour la NSA (agence civile), la NGA (agence militaire) et autre DGHQ, le Big Data prend une ampleur non pas astronomique (nous avons vu que les observatoires ne gèrent "que" quelques terabytes chaque nuit) mais prend carrément une envergure cosmique tout comme le secret qui l'entoure ! Le problème qui se pose aux agences de renseignements et à la NSA en particulier, est de localiser les criminels et autres terroristes et au besoin de les neutraliser. Malheureusement le territoire est vaste et selon une étude du cabinet Gartner, il y a plus de 9 milliards d'appareils connectés dans le monde... Mais parmi les milliards d'informations anodines échangées chaque seconde à travers les réseaux il y a quelques messages transmis par des terroristes et autres malfrats; ce sont ces messages, ces numéros de téléphones et ces individus que les services d'espionnage essayent d'identifier. A défaut de pouvoir cibler ses objectifs et de connaître le motus operandi de ces suspects, la NSA est obligée de ratisser large et donc d'espionner ses ressortissants (ainsi que certaines personnalités étrangères) en mettant "sur écoute" tous les moyens de communications, y compris Internet à travers les lignes Wi-Fi, GPS, les messageries publiques, les réseaux sociaux et autres forums. Selon la NSA, son nouveau data center installé à Bluffdale en Utah serait capable de contenir jusqu'à 1 yottabyte de données soit 1 million de milliards de gigabytes ! Ce data center peut stocker plusieurs années complètes de trafic Internet (estimé à 996 exabytes en 2015). Si on extrapole les valeurs calculées par Randall Munroe de What if?, 1 YB serait l'équivalent de 120 000 fois la capacité de production annuelle de l'industrie du disque dur ! Trafic sur les réseaux numériques Pour satisfaire les utilisateurs de ces data centers et des clients qui utilisent de plus en plus Internet, notamment les services multimédias qui exigent une large bande passante et un haut débit et les services du Cloud computing, l'infrastructure des télécommunications a dut être adaptée aux nouvelles technologies. Les lignes coaxiales par exemple ont été remplacées par de la fibre optique, les modems asynchrones par des routers et les ordinateurs monoprocesseurs par des systèmes multi-coeurs équipés de cartes graphiques à haute performance. Avec l'évolution de l'informatique et des télécommunications, en moyenne, le nombre de connexions à hauts débits double tous les 21 mois, suivant la loi de Nielsen. Ce taux est plus lent chez les particuliers. Mais un jour ou l'autre tout le monde sera contraint de convertir son installation à la fibre optique car le câble de cuivre (coaxial) ne sera plus supporté par l'opérateur. Ce progrès étant continu, on constate que la bande passante d'Internet (le débit des transferts de données) augmente de manière exponentielle chaque année[2]. Sur les câbles de télécommunications en fibre optique installés à travers le monde, le débit des données est actuellement (2012) de l'ordre 125 terabits par seconde (Tbits/s ou Tbps) dont 82.4% concernent le trafic Internet, 17.4% les réseaux privés (notamment d'entreprises) et 0.2% le téléphone.
Dans ce flux de 125 Tbits/s, 12.6 Tbits/s soit 10% sont destinés à l'Europe et 20.6 Tbits/s soit 16% sont destinés aux Etats-Unis qui représente le principal destinataire des communications. Que représente concrètement ces 12.6 Tbits/s destinés à l'Europe ? Ce flux de données représente chaque seconde le volume d'un disque dur de 1575 GB ou 25 clés USB de 64 GB ou 200 livres de 350 pages au format A5 ou environ 315000 photos de 5 MB ou encore 15.7 millions d'e-mails de 100 KB. Prochain chapitre La technologie de l'information au service du métier
|
|||||||||||||||||||||||||||||||||||||||||||||||||||